Table of Contents
Introduction
Modern geospatial platforms demand flexible infrastructure to ingest, analyse and serve large amounts of data. When designing the platform architecture and services involved, an important factor that we have to take into account is digital sovereignty – the ability to run software on our own terms and avoid cloud vendor lock‑in. We do this by relying on open‑source technologies and self‑hosted deployments.
This article describes a reference architecture for an Amazon Web Services (AWS) hosted platform built entirely from open‑source components. Instead of going for a full-blown Kubernetes control plane, we opted for using Nomad in order to simplify orchestration, and also to have the possibility to keep some services running on bare‑metal virtual machines, as opposed to containers.
The resulting platform provides multi‑region resilience, predictable costs and interoperability for geospatial data processing, analysis, hosting and management.
Open Source and Digital Sovereignty
All major components of the platform are free and open source. This provides autonomy and freedom to run software on infrastructure under your control.
As a company based in Norway, we support the EU Commission's ambitions to make open‑source software a central pillar of Europe’s strategy for digital autonomy. In the recent EuroStack initiative, the Commission has published an open letter which argues that the continent must build strategic autonomy across all layers of the stack – from chips and AI frameworks to cloud platforms.
Our platform uses tools and services like Plone, PostgreSQL/PostGIS, GeoServer, Prefect, FastAPI, and Grafana which are released under permissive licences. The orchestrator Nomad works together with Consul and Vault to provide service discovery, configuration and secrets management. Storage is handled by Amazon S3 (or self‑hosted alternatives like MinIO) and EBS, while compute nodes run on EC2 instances.
The platform also stays interoperable with open standards (SQL, OGC WMS/WFS, REST) and allows you to migrate workloads between clouds or to on‑premises machines.
Core architecture design principles:
- Open source and digital sovereignty – open-source components enable independence and control over data and services. The platform can be deployed in EU regions to comply with data sovereignty requirements.
- Multi‑region and high availability – critical services are replicated across at least three availability zones (AZs). Secondary stacks can be deployed to another AWS region for disaster recovery. Within a region, auto‑scaling groups distribute workloads across AZs.
- Separation of concerns – the architecture uses distinct layers for compute, data and observability. Each layer can scale independently and be secured with appropriate policies.
- Simplified ops – Nomad is used as the orchestrator because it can schedule both containerised workloads and traditional services. Unlike Kubernetes, Nomad consists of a single binary and has minimal dependencies, it's simpler to run and has the ability to run non‑containerised jobs.
Infrastructure as Code and Continuous Deployment
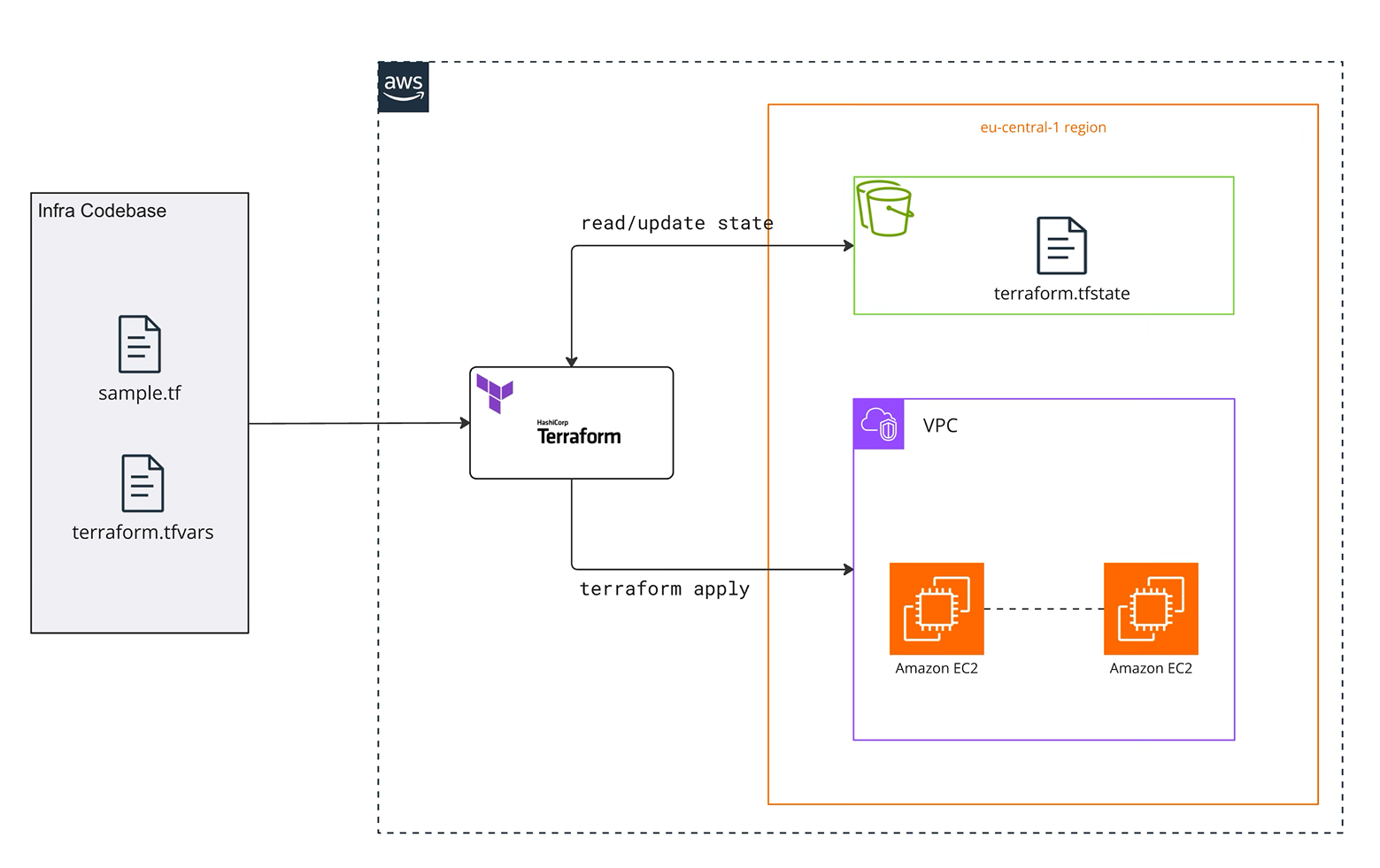
Provisioning and updating the platform is automated using Terraform and Github Actions. A GA workflow runsterraform plan and apply whenever changes are merged. State is stored in an S3 bucket with locking to prevent concurrent writes.
The diagram below illustrates how Terraform reads the infrastructure code, updates the remote state and applies changes to create a VPC and EC2 instances. The.tfvars file supplies region‑specific variables. The pipeline can be extended to deploy application code into Nomad via nomad job run.
Infrastructure Layers
The platform is organised in three-layer architecture which are specified below, together with containerisation status.
|
Layer |
Key Services |
Deployment Mode |
Orchestration |
|
Compute Layer |
API Gateway, Web UI, APIs, Plone CMS |
Docker Containers |
Nomad (Container Orchestration) |
|
Data Layer |
PostgreSQL, PostGIS, ERDDAP, GeoServer |
Bare Metal (EC2 VMs) or Docker Containers |
Nomad (raw_exec & system jobs or containers) |
|
Observability Layer |
Prometheus, Grafana, Loki, Alertmanager |
Docker Containers |
Nomad (Container Orchestration) |
Compute Layer (Application & Data Processing)
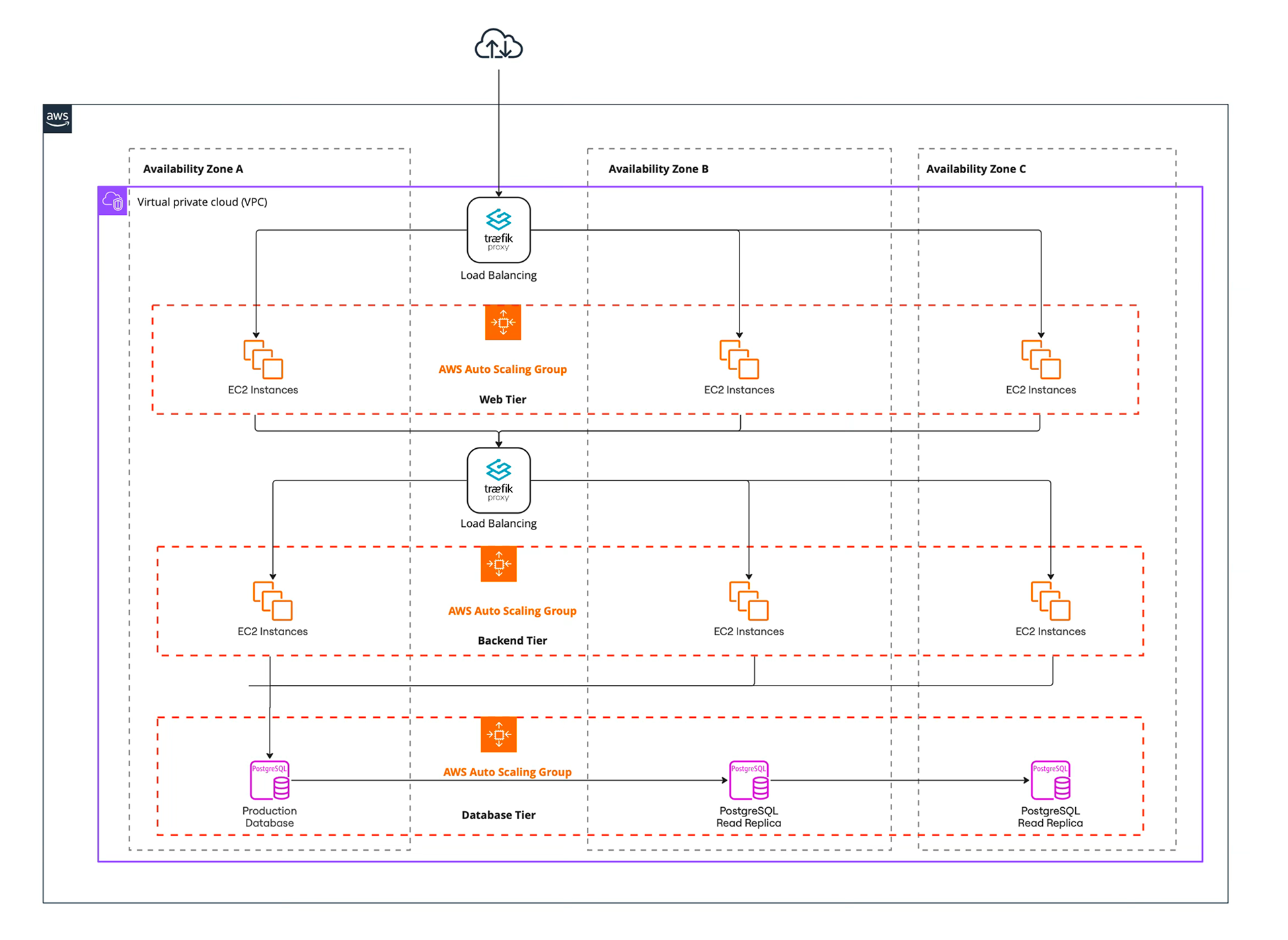
The compute layer runs both long‑lived services and batch jobs. EC2 instances are grouped into auto‑scaling groups across multiple AZs. Edge proxies (Traefik) listen on public subnets and route requests to services running on Nomad clients in private subnets.
Service discovery is handled by Consul, while secrets are managed by Vault. Nomad schedules applications such as Plone (UI/CMS), FastAPI (Backend services), Prefect (ETL) flows and the Traefik ingress gateway. Non‑containerised workloads can be run as raw executables.
The diagram below shows the Nomad cluster architecture with servers and clients spread across three AZs. A failure in one AZ does not disrupt operations because Nomad, Consul and Vault elect new leaders and reschedule workloads on healthy nodes.
GeoServer Deployment
The platform is oriented towards geospatial data services and applications and so it requires some specialised services.
GeoServer serves as the primary tool for rendering and delivering geospatial data layers. It can interact directly with the PostgreSQL database (with PostGIS extensions) to pull geospatial data, which can then be visualised on the frontend using Leaflet or OpenLayers.
It provides INSPIRE-compliant geospatial data visualisation via OGC Web Services (WMS, WFS, WMTS). It supports the foundation for the map viewer implementation, fully compatible with platforms such as EMODnet – European Marine Observation and Data Network.
Data Stores
GeoServer will be configured to connect to the PostgreSQL/PostGIS database as a data store. This connection enables GeoServer to access geospatial data stored in the database, such as campaign locations, sampling areas, and other relevant spatial features.
Layer Configuration
Each dataset within the database will be exposed as a layer in GeoServer. These layers will be configured with appropriate styles (SLD - Styled Layer Descriptor) to represent different types of data (e.g., points for campaign locations, polygons for sampling areas). Layers can be cached using GeoWebCache for faster rendering.
Deployment
|
Component |
Implementation |
|
Hosting Environment |
Containerised service, orchestrated by Nomad. |
|
Storage Backend |
Uses PostGIS-enabled PostgreSQL for geospatial data |
|
Security |
OAuth2-based authentication via Keycloak |
|
Load Balancing |
Handled by Traefik |
|
Cache Optimization |
TileCache (GeoWebCache) optimises WMS responses |
|
Availability |
Multiple GeoServer instances support horizontal scaling |
|
Observability |
Logs and metrics are centralised in the Observability service (Loki + Grafana + Prometheus) |
Authentication & Authorisation
Identity and access control are managed by Keycloak, an open‑source identity and access management system. Keycloak provides single sign‑on and single sign‑out so that users authenticate once and can access multiple applications without re‑login, and logging out from one application logs them out everywhere.
Responsibilities:
- Enables SSO across all platform components (Plone CMS, API services, ETL pipelines, dashboards)
- Supports OAuth 2, OpenID Connect (OIDC), and SAML 2.0 authentication flows
- Provides Role-Based Access Control (RBAC) for API endpoints
- Compliance with EU data sovereignty and Zero Trust security models.
The zero‑trust model is enforced via Traefik and AWS Secrets Manager, ensuring credentials and secrets remain out of application code. Keycloak also supports identity brokering and can federate with external LDAP or social identity providers when required.
Deployment Model:
|
Component |
Implementation |
|
Hosting Environment |
Containerised service, orchestrated by Nomad. |
|
Storage Backend |
Uses PostgreSQL for persistent identity storage |
|
Networking |
Runs behind Traefik for TLS termination and API routing |
|
Load Balancing |
Managed by Traefik |
|
Security |
Multi-Factor Authentication (MFA) and Role-Based Access Control (RBAC) |
Scalability Considerations:
- Horizontal scaling: additional KeyCloak instances auto-provisioned via Nomad
- PostgreSQL replication: high-availability and read performance optimisation
- Session clustering: KeyCloak HA mode ensures session persistence across multiple instances
- Token Caching: optimised caching reduces API authentication latency.
Example Authentication Workflow with EU Login
KeyCloak integrates with EU Login using OAuth 2.0, a widely adopted authorisation framework.
When a user attempts to log in, they are redirected to the EU Login portal, where they authenticate using their credentials. Upon successful authentication, EU Login issues an OAuth 2.0 token, which is passed back to KeyCloak. KeyCloak then uses this token to authenticate the user and establish a session.

The authentication process follows the OAuth 2.0 authorisation flow, with KeyCloak managing the access token issues by the EU Login service, and issuing a session token to the web application.
Data Layer (Storage & Processing)
The Data Layer contains databases, geospatial services, and external dataset integration. The platform needs to serve structured, unstructured and semi‑structured datasets.
The Data Layer contains databases, geospatial services, and external dataset integration.
|
Service |
Instance Type |
Autoscaling (Min - Max) |
VPC Setup |
|
PostgreSQL + PostGIS |
r5.large |
2 - 4 (HA Cluster) |
Private VPC |
|
GeoServer |
t3.medium |
2 - 4 |
Private VPC |
|
ERDDAP |
m5.medium |
1 - 2 |
Private VPC |
|
Amazon S3 |
Managed |
Auto-Scaling |
Private IAM-restricted |
- Relational data. A primary PostgreSQL/PostGIS instance stores user accounts, metadata and application data. One or more read replicas serve API queries. Streaming replication ensures minimal data loss during failover.
- Object storage. Amazon S3 (or MinIO on self‑hosted servers) holds large files such as raw sonar data, Cloud Optimised GeoTIFFs, Zarr archives and Parquet tables. We organise data into versioned buckets and use lifecycle policies to move older data to lower‑cost storage classes.
- File systems. EBS volumes store the Postgres database, logs and caches. Because EBS volumes are bound to an AZ, we schedule backups to S3 and replicate snapshots to other regions for durability.
- Data services. Geospatial datasets are published via GeoServer (OGC WMS/WFS/WCS) and ERDDAP. These services run in Nomad tasks on their own EC2 instances. APIs implemented in FastAPI provide programmatic access.
- Data processing and pipelines. Data ingestion, conversion and analytics are orchestrated with Prefect 3. Python libraries such as echopype, Zarr, xarray and Dask process sonar data into analysis‑ready formats. Prefect tasks run in Nomad with concurrency control and retries.
Observability Layer (Monitoring & Logging)
The observability stack records metrics, logs and alerts. It is deployed in a separate security group and accessible only through VPN or IAM‑authenticated users.
The core components are:
|
Service |
Instance Type |
Autoscaling (Min - Max) |
VPC Setup |
|
Prometheus |
t3.medium |
1 - 3 |
Private VPC |
|
Grafana |
t3.medium |
1 - 2 |
Private VPC |
|
Loki |
t3.medium |
1 - 3 |
Private VPC |
|
Alertmanager Failure Alerts |
t3.small |
1 - 2 |
Private VPC |
Security Measures
- Prometheus collects system and application metrics. Node exporters on each EC2 instance publish CPU, memory and disk usage. Application metrics are exposed via HTTP endpoints. Prometheus stores time‑series data locally and replicates it to S3 for long‑term retention.
- Grafana provides real‑time dashboards. It queries Prometheus and Loki to display health metrics and logs. Grafana dashboards include CPU and memory utilisation per service, request latency, database throughput and queue depths. An alerting framework notifies operators via email, Slack or PagerDuty.
- Loki aggregates logs from Nomad tasks and systemd journal via promtail. Logs are indexed by labels such as
job,namespaceandinstancebut not full‑text, keeping storage efficient. Queries allow you to filter logs by service, time and severity. - Alertmanager deduplicates and groups alerts from Prometheus and pushes them to notification channels. Alerts are configured to trigger when thresholds are exceeded (e.g., CPU > 80 %, database replication lag > 30 seconds).
Beyond metrics and logs, the stack can be extended with OpenTelemetry to collect traces from microservices and measure end‑to‑end latency. This facilitates root‑cause analysis when multiple services are involved in a request.
Security and Certificate Management
The platform follows zero‑trust principles. All services run within private subnets and communicate via encrypted channels. Network traffic is restricted by security groups and NACLs.
TLS certificates are issued by the controlling authority and stored securely in AWS Secrets Manager. Traefik terminates TLS connections and routes requests to backend services.
The following table summarises SSL/TLS certificate management:
|
Function |
Implementation |
|
Certificate Issuance |
Certificates issued by the relevant authority. |
|
Certificate Storage |
Stored securely in AWS Secrets Manager via Terraform. |
|
SSL Termination |
Traefik manages certificate-based HTTPS termination. |
|
Renewal Strategy |
Manual or automated renewal; updated in Secrets Manager and reloaded by Traefik. |
High Availability & Failover Strategy
Nomad provides a lightweight, easy-to-manage alternative to Kubernetes while supporting both containerised and non-containerised workloads.
In case of an AZ outage, Traefik automatically redirects traffic to services in the remaining AZs. PostgreSQL uses streaming replication to maintain a warm standby in another AZ.
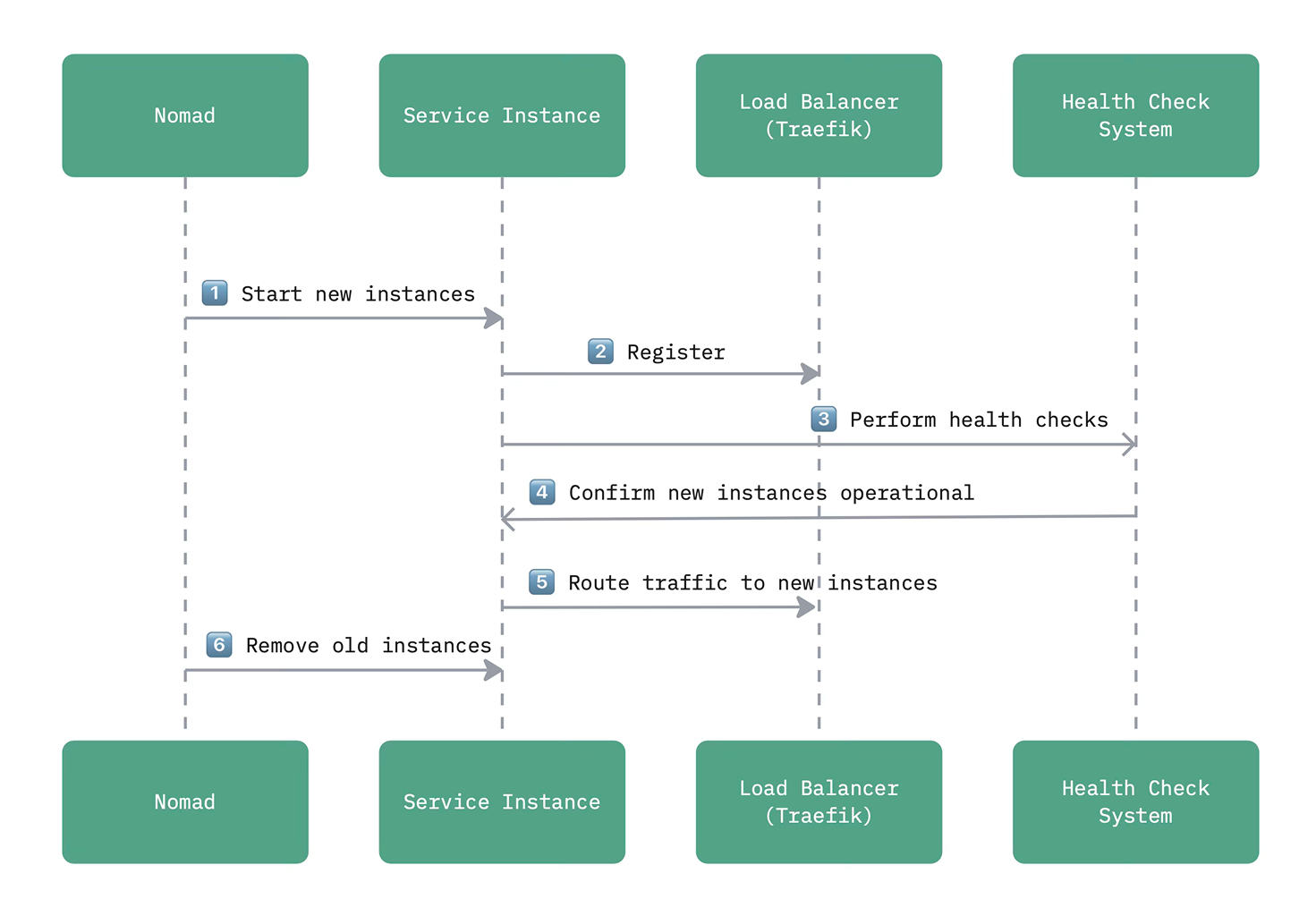
A rolling update strategy ensures zero downtime when deploying new versions: Nomad starts new instances, Traefik routes traffic to the healthy pods and old instances are gracefully terminated after passing health checks.
The following diagram illustrates the rolling update sequence.
Multi‑region Resilience and Disaster Recovery
For mission‑critical applications, a single region may not be sufficient. AWS regions occasionally experience power failures or network outages. To protect against region‑level events, the platform can be duplicated in a secondary region. Data replication is achieved via asynchronous database replication (streaming WAL logs to a replica), cross‑region object replication (S3 replicates objects to a bucket in the failover region) and reusable Terraform modules to provision identical stacks. Vault can be unsealed in the new region and secrets injected into Nomad tasks.
Disaster Recovery Principles
The architecture follows a fault-tolerant and auto-recoverable infrastructure, using Terraform for provisioning, Nomad for orchestration, and high-availability databases and services.
|
Requirement |
Implementation |
|
System Downtime < 2 hours |
Auto-recovery workflows, multi-AZ deployment. |
|
Data Loss Prevention |
Multi-level backups, read-replicas, continuous WAL archiving. |
|
Regular Maintenance |
Security patches, OS updates, application versioning. |
|
Periodic Usage Reporting |
Automated AWS resource allocation & monitoring logs. |
Recovery Time and Recovery Point Objectives
|
Metric |
Target |
|
Recovery Time Objective (RTO) |
≤ 2 hours |
|
Recovery Point Objective (RPO) |
≤ 5 minutes (for databases), ≤ 24 hours (for archived datasets) |
When designing for multi‑region failover, it is important to consider data transfer fees. AWS charges for inter‑region data replication; typical rates range from $0.02 to $0.17 per GB depending on the source and destination[8]. In our cost model we assume 1 TB per month replicated at $0.02/GB.
Cost Estimation
One advantage of running your own platform is the ability to predict and control costs. The table below summarises monthly costs for the example architecture using on‑demand pricing.
Prices are approximate and vary by region and time; we use publicly available per‑hour costs for EC2 instances as of 2025. Storage costs are based on list prices for EBS gp3 and S3 Standard‑Infrequent Access.
|
Service |
Instance type |
Count |
Price (USD/h) |
Monthly cost (USD) |
|
Traefik proxy |
t3.medium |
2 |
0.0416 |
≈60.74 |
|
Nomad servers |
t3.large |
3 |
0.083 |
≈181.77 |
|
Consul servers |
t3.small |
3 |
0.0208 |
≈45.55 |
|
Vault servers |
t3.medium |
3 |
0.0416 |
≈91.10 |
|
Backend services |
t3.large |
4 |
0.083 |
≈242.36 |
|
PostgreSQL primary |
r5.large |
1 |
0.126 |
≈91.98 |
|
PostgreSQL replica |
r5.large |
1 |
0.126 |
≈91.98 |
|
GeoServer |
t3.medium |
2 |
0.0416 |
≈60.74 |
|
ERDDAP |
m5.medium |
1 |
0.048 |
≈35.04 |
|
Prometheus |
t3.medium |
1 |
0.0416 |
≈30.37 |
|
Grafana |
t3.medium |
1 |
0.0416 |
≈30.37 |
|
Loki |
t3.medium |
1 |
0.0416 |
≈30.37 |
|
Alertmanager |
t3.small |
2 |
0.0208 |
≈30.37 |
|
Compute total |
≈1,022.73 |
|||
|
EBS gp3 storage (2×1 TB + 200 GB logs) |
— |
— |
0.08 per GB‑month |
≈179.84 |
|
S3 Standard‑IA (10 TB) |
— |
— |
0.0125 per GB‑month |
≈128.00 |
|
Inter‑region data transfer (1 TB) |
— |
— |
0.02 per GB |
≈20.48 |
|
Estimated monthly total |
≈1,351.05 |
|||
The compute total assumes on‑demand pricing. Reserved or spot instances can reduce costs by 30–70 %. Storage costs scale linearly with capacity; storing 5 TB instead of 10 TB would halve the S3 cost. Data transfer fees depend on replication volume and the number of read requests served from the secondary region.
Conclusion
Building your own cloud platform may seem like a large effort, but with careful design and open‑source tools it becomes manageable and cost‑effective.
Using Nomad instead of Kubernetes simplifies operations and run both containerised and bare‑metal workloads. A multi‑region AWS deployment with EC2, EBS and S3 provides high availability and disaster recovery.
Data sovereignty is preserved by choosing EU regions and self‑hosted services. The estimated monthly cost of around $1.35 k is competitive with managed solutions, and could be reduced further by using reserved or spot instances.
The architecture described here is only a starting point. Real‑world deployments will be tailored to specific workloads, compliance requirements and organisational constraints. Nonetheless, it demonstrates that an open‑source stack can power a modern geospatial data platform at scale.
We can help your organisation deploy cloud-native data platforms using open-source services, on both AWS and Azure. Contact us to discuss your use-case and setup a collaboration plan.